Interesting videos, distilled.

How This Ex-Meta L8 Engineer Ships 40 PRs a Day with AI Agents | Kun Chen
Kun’s thesis is that AI-agent coding changes the bottleneck from typing code to specifying, isolating, validating, and coordinating many agent runs. The engineer’s job shifts toward product judgment, spec quality, workflow design, and risk-based review. I agree with the direction, but not with the strongest interpretation that humans should generally leave t

Yann LeCun: World Models: Enabling the Next AI Revolution
LeCun argues that today’s dominant generative and language-model approaches are insufficient for grounded intelligence. Human and animal intelligence is adaptive: it learns from observation, builds predictive abstractions of the world, and plans by optimizing over imagined outcomes. The proposed path is joint-embedding predictive architectures, energy-based

The Production AI Playbook: Deploying Agents at Enterprise Scale — Sandipan Bhaumik, Databricks
Production AI fails when teams treat models as the center of the system. Bhaumik argues that reliable enterprise agents require five pillars before and during implementation: evaluation, observability/tracing, data foundation, orchestration, and governance. The memorable formulation is that production AI must be visible, measurable, and accountable.

The best AI agents are simpler than you think
The best production agents are often simpler at the user-facing level — one brand-representing agent with excellent context, evals, governance, and workflow fit — but complex under the hood where latency, retrieval, model routing, payments, memory, and monitoring are engineered as separate reliable subsystems.

The Future of AI Agents with Andrew Ng | Interrupt 26
Ng’s thesis is that coding agents have accelerated software creation enough that the scarce resource shifts from writing code to deciding, coordinating, verifying, and commercializing what should be built. The future team is smaller, more technical, more generalist, and more dependent on fresh context, evals, guardrails, and data architecture.

Software engineering at the tipping point
Software engineering is entering an AI-driven “tipping point,” but the main risk is not just faster code generation. The main risk is systemic: AI amplifies existing developer ecosystems. Strong cultures, platforms, feedback loops, and validation strategies can channel that amplification productively; weak ones may get more code, more noise, more risk, and l

Building Agent Interfaces: Lessons from Chrome DevTools (MCP) for Agents — Michael Hablich, Google
Agents are a distinct user class. They may share human goals—debug the page, fix the layout, improve performance—but their bottlenecks differ: context size, tool-selection ambiguity, recovery loops, and security/trust boundaries. Building good agent interfaces therefore means designing the “UI” as schemas, summaries, tools, recovery hints, metrics, and permi

Everything We Got Wrong About Research-Plan-Implement — Dexter Horthy
Research-Plan-Implement was useful but too monolithic and too dependent on expert prompting. The revised thesis is: do not outsource engineering thinking, do not trust huge plans as the review target, keep research factual, align on design and structure in short artifacts, then read and own the code.

BDD, ADR, PRD, WTF: Capturing Decisions for Humans and AI Alike — Michal Cichra, Safe Intelligence
AI makes old software-memory problems show up faster. Teams already forgot why flows, features, and architecture exist; LLM agents also lose context, compact conversations, and have no durable memory unless decisions are written down and linked to enforcement. Cichra’s thesis is that ADRs, PRDs, BDD, design systems, hooks, CI, skills, and linters form a prac

Dark Factory: OpenClaw Ships Faster Than You Can Read the Diff — Vincent Koc, OpenClaw
Vincent argues that AI-assisted software work is moving from individual coding to “factory management”: many concurrent agent sessions, reusable skills, orchestration, evals, and human judgment. The provocative commit counts are less important than the operating model: engineers become supervisors of many semi-autonomous development lanes, and the bottleneck

GPT-5.5 深入解析:為什麼從 Claude Code 跳到 Codex? — Just Kidding Tech
GPT-5.5 plus the newer Codex app experience made Codex feel like a more complete everyday agent environment than Claude Code for this creator/developer’s workflow. The practical shift is from “which model writes better code?” to “which agent environment can run the whole work loop: plan, implement, test in browser, operate the computer, use plugins, manage s

Building a Second Brain: Opportunities, Risks, and Implications for AI Adoption in Singapore — Dr Vivian Balakrishnan
AI adoption creates the most value when ordinary practitioners use available tools to redesign their own workflows. But the human still owns understanding, judgment, and accountability. A useful second brain should augment a person’s work, not replace their responsibility.

The AI Skill I Rely On Daily — Priscila Andre de Oliveira, Sentry
The biggest unlock from AI in a large production codebase is not raw code generation; it is comprehension. AI becomes valuable when it helps engineers build, update, and verify their mental model of a complex, fast-moving system before they plan or ship changes.

Engineering voice agents: latency, quality, and scale — Rishabh Bhargava, Together AI
Voice agents are no longer primarily a research demo problem; they are a systems engineering problem where latency, intelligence, naturalness, reliability, observability, and scale all have to be solved simultaneously. The current production-favored answer is a cascaded STT → LLM/tools → TTS pipeline, while the future likely shifts toward speech-to-speech mo

How OpenAI's Codex Team Builds with Codex — Alex & Romain
The Codex team is building and using Codex as a delegation surface: fewer heavyweight specs, more parallel agent work, more builders across roles, and product design that makes multiple agents feel natural. Their workflow bets that as models improve, the scarce human work becomes choosing what to build, maintaining quality, staying close to users, and assign

How I deleted 95% of my agent skills and got better results — Nick Nisi, WorkOS
Nick’s thesis is not “skills are bad.” It is: agents perform better when their environment enforces evidence, measures outcomes, and gives concise product-specific gotchas instead of large instruction blobs. The developer’s job shifts from writing every line to designing the harness that makes good behavior easier than lying or drifting.

AIE Singapore Day 1 ft. Minister, NanoClaw, OpenAI, Google, Vercel, Cursor & more
Analysis generated from transcript, comments, screen evidence, and research.

AIE Singapore Day 2 ft. Google DeepMind, OpenClaw, Adaption, Arize, Cloudflare, Robot Company & more
Analysis generated from transcript, comments, screen evidence, and research.

Claude Agent SDK [Full Workshop] — Thariq Shihipar, Anthropic
The Claude Agent SDK packages lessons from Claude Code into an opinionated way to build agents: Unix-like primitives, bash/filesystem context engineering, code generation for non-coding tasks, skills, sub-agents, hooks, memory, permissions, and verification loops. The practical message is to prototype simply, verify aggressively, and only productionize what

DSPy: The End of Prompt Engineering — Kevin Madura, AlixPartners
DSPy reframes prompt engineering as programming: define signatures, modules, tools, adapters, metrics, and optimizers so LLM calls become composable, typed, inspectable parts of a Python program. The “end of prompt engineering” claim is rhetorical; the stronger claim is that prompts should be generated, evaluated, and optimized inside a programmatic system.

Build a Prompt Learning Loop — SallyAnn DeLucia & Fuad Ali, Arize
Prompt learning is a feedback loop for improving agent instructions using failed traces, human/SME explanations, and LLM-judge explanations. It sits between manual prompt editing and heavier fine-tuning: cheaper than model training, but more disciplined than “ask an LLM to make the prompt better.”

Leadership in AI Assisted Engineering — Justin Reock, DX / Atlassian
AI-assisted engineering leadership is less about forcing usage and more about building a trustworthy operating system around AI: psychological safety, education, measurable outcomes, prompt/rule feedback loops, compliance partnership, and bottleneck-focused SDLC integration.

Can Cursor's HARDCORE Review Skill Stop The Slop?
A strict AI review skill can surface meaningful architecture and maintainability problems that ordinary agent coding misses, but it needs shorter, clearer instructions, stronger test/feedback-loop requirements, and a way to manage false positives and repeatability.

Context Graphs for Explainable, Decision-Aware AI Agents — Andreas Kollegger & Zaid Zaim, Neo4j
Neo4j’s thesis is that AI agents need more than retrieved facts and prompt instructions: they need structured context graphs that combine memory, policies, rules, precedent, authority, and risk/value reasoning so agents can explain why they acted and decide when not to act.

Ship your first Managed Agent — synthesized analysis
Claude Managed Agents is presented as a production-oriented agent harness: Anthropic runs the long-lived agent loop, session state, observability, sandbox/tool runtime, and scaling primitives so developers can focus on domain context, tools, and policy. The workshop grounds that thesis in a concrete SRE incident-response demo: define an agent, attach an envi

100 Hours Testing Claude Code vs ChatGPT Codex — honest results
Codex vs Claude Code is not a universal winner question: Claude Code is stronger as a customizable workflow substrate, while Codex is stronger as an opinionated shipping product integrated with ChatGPT/OpenAI surfaces.

Run Frontier AI at Home — Alex Cheema, EXO Labs
Frontier-capable AI should not depend entirely on centralized clouds; local/distributed inference can reduce dependency, improve privacy/control, and exploit under-optimized consumer hardware—but it remains technically messy.

Hermes Agent Kanban Feature — Multi-Agent Content Pipeline
Hermes Kanban turns a single-agent chatbot into a visible task-coordination surface for parallel specialist agents, demonstrated through a content pipeline backed by Supabase.

35 Claude Code skills on GitHub — GitHub Awesome
The episode is a fast catalog of open-source agent skills; the durable takeaway is that reusable domain procedures are becoming the practical unit of agent customization.

Stop babysitting your agents — Brandon Waselnuk, Unblocked
Agents fail less because they get larger context windows or more tools; they fail less when organizations provide curated, conflict-aware, runtime context.

What the Best Agents Share — Mardu Swanepoel, Flinn AI
Great agents are not just smarter models; they are product systems that constrain attention, reveal process, absorb user/domain knowledge, and make mistakes reversible.

Why Rust is the Ideal Language for Vibe-Coding — Daniel Szoke, Sentry
Daniel Szoke argues that the popular “vibe coding” language choice is backwards. Python, JavaScript, and TypeScript are attractive because models can produce runnable code quickly, but that looseness can hide mistakes. Rust is better for serious agentic coding because its compiler and type system constrain the model, expose mistakes early, and provide concre

The maturity phases of running evals — Phil Hetzel, Braintrust
Evals mature from informal human judgment into a production feedback system. The path is not “write perfect tests for every possible failure.” Instead, teams start with documented human judgment, extract failure modes, automate the parts that can be automated, then close the loop by replaying production traces through offline experiments. Phil’s central dist

Bounded Autonomy: Between Free Will and Determinism — Angus J. McLean, OLIVER
Autonomy is most useful when bounded by constraints: curated context, small/simple harnesses, explicit representations, short feedback loops, and domain-specific evaluation. More model power and more context are not automatically better; sometimes constraints improve control, creativity, and understanding.

Agentic Evaluations at Scale, For Everybody — Nicholas Kang & Michael Aaron, Google DeepMind / Kaggle
AI evals are too scattered, stale, opaque, and lab-centric. Kaggle/DeepMind want more community-built, transparent, reusable, and scalable eval infrastructure: hackathons for benchmark creation, standardized agent exams for consumer agents, PvP game arenas for unsaturated leaderboards, and a benchmark platform for domain-specific tasks.

Does GenAI “belong” to data scientists? — Phil Hetzel, Braintrust
GenAI agents should not be owned exclusively by data scientists or ML engineers. Data scientists bring crucial risk, testing, statistical, fine-tuning, and judge-calibration skills; product engineers and domain experts bring API/system design, user-problem proximity, prompt/context judgment, and annotation. The practical answer is a cross-functional product

Fast Models Need Slow Developers — Sarah Chieng, Cerebras
Ultra-fast coding models change the developer role: they make validation, exploration, steering, and frequent refactoring cheap, but they also make it easier to generate unreviewed technical debt at dangerous speed. The answer is slower, more deliberate human workflow — smaller tasks, real-time steering, externalized memory, and constant verification.

Lobster Trap: OpenClaw in Containers from Local to K8s and Back — Sally Ann O'Malley, Red Hat
OpenClaw and similar always-on agent runtimes should be packaged like serious infrastructure: reproducible containers locally, Kubernetes/OpenShift for scaled deployments, platform-managed secrets, persistent volumes for memory/state, and curated baselines for teams.

Your Coding Agent Should Do AI System Engineering — Ben Burtenshaw, Hugging Face
Coding agents can move beyond CRUD/product-code tasks into AI systems engineering — CUDA kernels, fine-tuning, and automated research — but only when the ecosystem exposes standard, open, reproducible primitives: skills, benchmark scripts, hub repositories, compatibility metadata, jobs, and tracking.

How we Claude Code
As coding agents become capable of longer-running, more complex work, teams need to change the artifacts around them: let the agent extract requirements interactively, use richer human-readable planning artifacts when Markdown becomes unreadable, and make verification native to the built artifact so both humans and agents can inspect the same runtime truth.

I Tried Every Popular Claude Skills System, Here is the Best
The video argues that popular Claude/agent skill systems mostly rediscover the same software-development loop: clarify the work, prototype where useful, plan small slices, build incrementally, test, review, simplify, and ship. The creator's distinctive claim is that the best skill system is not someone else's repo; it is the lightweight, evolving harness you
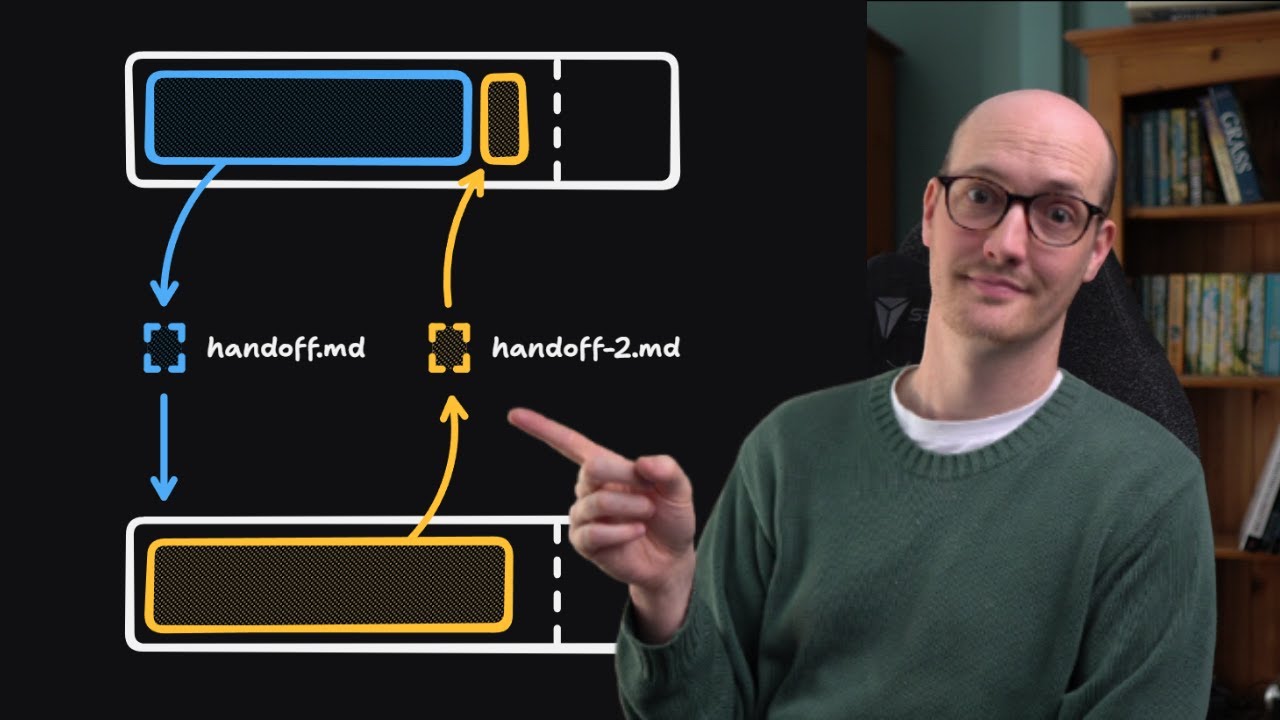
/handoff is my new favourite skill
The video argues that a handoff skill is valuable because modern agent work is not one linear conversation. You often need to branch work into separate sessions, preserve the parent context, prototype uncertain areas, file issues, or resume later. A good handoff document deliberately compresses only the relevant slice of context so another agent can act with

Running an AI-native engineering org
The talk argues that AI-native engineering does not merely make coding faster; it moves the bottleneck to verification, planning, review, ownership, onboarding, and knowledge sharing. Teams should rewrite norms around those new bottlenecks rather than preserving rituals designed for an era when engineering typing bandwidth was scarce.

My Full Claude Cowork Setup (steal my workflows!)
The video presents a personal Claude Cowork operating system: configure the assistant with PRD-first rules, pushback, documentation, and reversibility; design an initial PRD for your workspace; build a folder/data architecture; then layer daily digest, dashboards, research, meeting prep, and autonomous builder workflows on top.

This Is The Best Local Model Runner For Apple Silicon (oMLX)
oMLX is promising for local Apple Silicon agent workloads because it combines MLX unified memory with persistent KV caching, but claims depend heavily on hardware and benchmark conditions.

Graphify Solves Claude's Biggest Limitation (Finally)
Knowledge graphs can improve codebase research for AI assistants, but token-savings claims must be benchmarked on your repo and workflow.

Top 5 Claude Cowork Tips I Wish I Knew from Day One
A useful Claude Cowork setup is mostly disciplined markdown operations: lean root instructions, separate memory, routed references, and file-governance rules.

The Agent Development Lifecycle: Build, Test, Deploy, Monitor | Interrupt 26
Agents need an SDLC: build with tools/state, test trajectories, deploy stateful runtimes, monitor unique agent data, and govern the loop.

AI Coding Interview w/ Meta Staff Engineer
AI-enabled coding interviews reward judgment: use the assistant for comprehension, test design, and bug isolation while owning correctness and tradeoffs.

Deep Dive: How to Monitor AI Agents in Production
Production agent monitoring must capture semantic inputs, trajectories, intermediate tool calls, and eval feedback, not only APM golden signals.

Skill issue: Lessons from skilling up coding agents to use Langfuse - Marc Klingen, Clickhouse
Coding-agent skills work best as live, structured navigation layers over docs, APIs, and traces, not as static prompt dumps.

From 46% to 90%: Fine-Tuning Tiny LLMs for On-Device Agents — Cormac Brick, Google
On-device agents become useful when tiny models are specialized for tool/function calling rather than treated as shrunken chatbots.

Herdr: the Tmux for AI Agents
The useful shift is not “let AI write more code”; it is designing an operating loop where agents have the right context, tools, triggers, isolation, verification, and human control points. The video is strongest when treated as workflow design evidence, not as proof that autonomy removes engineering responsibility.

Running an AI-native engineering org
The useful shift is not “let AI write more code”; it is designing an operating loop where agents have the right context, tools, triggers, isolation, verification, and human control points. The video is strongest when treated as workflow design evidence, not as proof that autonomy removes engineering responsibility.

Coding is no longer the constraint: Scaling devex to teams and agents at Spotify
The useful shift is not “let AI write more code”; it is designing an operating loop where agents have the right context, tools, triggers, isolation, verification, and human control points. The video is strongest when treated as workflow design evidence, not as proof that autonomy removes engineering responsibility.

From one person to 80: Scaling a hypergrowth engineering org with Claude Code
The useful shift is not “let AI write more code”; it is designing an operating loop where agents have the right context, tools, triggers, isolation, verification, and human control points. The video is strongest when treated as workflow design evidence, not as proof that autonomy removes engineering responsibility.

AI with Claude on AWS: From code to orchestration
The useful shift is not “let AI write more code”; it is designing an operating loop where agents have the right context, tools, triggers, isolation, verification, and human control points. The video is strongest when treated as workflow design evidence, not as proof that autonomy removes engineering responsibility.

What's new in Claude Code
The useful shift is not “let AI write more code”; it is designing an operating loop where agents have the right context, tools, triggers, isolation, verification, and human control points. The video is strongest when treated as workflow design evidence, not as proof that autonomy removes engineering responsibility.

Stop babysitting your agents
The useful shift is not “let AI write more code”; it is designing an operating loop where agents have the right context, tools, triggers, isolation, verification, and human control points. The video is strongest when treated as workflow design evidence, not as proof that autonomy removes engineering responsibility.

Build a proactive agent workflow with Claude Code
The useful shift is not “let AI write more code”; it is designing an operating loop where agents have the right context, tools, triggers, isolation, verification, and human control points. The video is strongest when treated as workflow design evidence, not as proof that autonomy removes engineering responsibility.

I Replaced Claude Design… 100% UNLIMITED — technical analysis
The video argues that Claude Design’s visual artifact workflow is valuable, but its limits and closed Anthropic-only model path are constraining; Open Design recreates much of the workflow locally and lets users route design generation through whatever coding agents, APIs, and model providers they already use. My read: the thesis is directionally right. Open

Google I/O 2026 keynote in 35 minutes — technical analysis
Google’s I/O 2026 keynote argues that Gemini is moving from a chatbot layer into an agentic operating layer across Google’s product surface: Search, Chrome, Workspace, YouTube, Gemini app, Android/XR, developer tools, creative tools, and cloud-hosted personal agents. The deepest shift is not any one model demo; it is Google trying to make Gemini the default

What Karpathy Joining Anthropic Actually Means For Claude — technical analysis
Karpathy joining Anthropic is best read as a convergence between two things: Anthropic’s product push around Claude/Claude Code as an agentic work environment, and Karpathy’s public focus on context engineering, LLM-maintained knowledge bases, and AI-assisted research loops. The model still matters, but the durable advantage increasingly sits in the wrapper:

Open Design: Why 40k Developers Abandoned Claude Design
Open Design is interesting because it moves AI design work away from a single proprietary canvas/model and toward a local-first, agent-agnostic workflow: choose a coding agent, combine it with skills and design systems, generate a concrete artifact, then export or hand it to an implementation agent. The tradeoff is that Claude Design’s integrated model/produ

How to Leverage Domain Expertise — Chris Lovejoy, Notius Labs
Chris Lovejoy argues that winning in vertical AI is less about finding the single “best model” and more about building a domain-native organization: a company structure that can continuously inject expert judgment into product quality, evaluation, and improvement. The talk’s central framework is that domain experts can act as Oracle (directly adding expertis

Ship Real Agents: Hands-On Evals for Agentic Applications — Laurie Voss, Arize
Agent teams should treat evals as tests powered by traces: inspect real failures first, then combine deterministic, built-in, LLM, meta-eval, dataset, and experiment loops before shipping.

Connecting the Dots with Context Graphs — Stephen Chin, Neo4j
Context graphs can make agent memory and retrieval more structured by connecting enterprise entities, decisions, and traces; the strongest use case is auditable, relationship-heavy context, not replacing all simpler RAG.

Self-Training Agents: Hermes Agent, HF Traces, Skills, MCP & Finetuning — Merve Noyan, Hugging Face
The Hugging Face ecosystem is becoming an agent platform: open models, inference routing, MCP, skills, trace datasets, and local/remote agents can be combined into a self-improving workflow, but the talk is more ecosystem tour than proof of self-training.

CI/CD Is Dead, Agents Need Continuous Compute and Computers — Hugo Santos and Madison Faulkner
Agent-generated code increases PR/change volume and stresses existing CI queues, caches, merge workflows, and review loops; the “CI/CD is dead” framing is overhyped, but CI infrastructure needs more concurrency-aware orchestration.

One Login to Rule Them All: Cross-App Access for MCP — Garrett Galow, WorkOS
Enterprise MCP adoption is blocked by fragmented OAuth consent and unmanaged standing credentials; Cross-App Access tries to let trusted clients and servers rely on the enterprise IdP for policy-controlled access.

Judge the Judge: Building LLM Evaluators That Actually Work with GEPA — Mahmoud Mabrouk, Agenta AI
Generic “hallucination judge” prompts are weak; useful LLM judges must be calibrated against human-labeled, use-case-specific data and validated like any other model component.

Why this Claude Code engineer uses HTML files as AI specs | Thariq Shihipar (Anthropic)
Use HTML, not just Markdown, for agent plans/specs when the audience is a human who must actually review, compare, and steer long-running coding work.

Full Walkthrough: Workflow for AI Coding — Matt Pocock
AI coding works best when treated like disciplined software engineering: keep tasks inside the model’s “smart zone,” use grill/PRD/issue slicing loops, parallelize independent work, and maintain human review checkpoints.

Build Agents That Run for Hours (Without Losing the Plot) — Ash Prabaker & Andrew Wilson, Anthropic
Prabaker and Wilson argue that long-running agents do not succeed because of model intelligence alone. They need harnesses: persistent artifacts, clean state, scoped roles, explicit verification, and feedback loops that let agents work across hours or days without losing context, prematurely declaring victory, or mistaking surface-level output for working so

The AI Career Opportunity Nobody is Talking About in 2026
Nate Herk argues that the under-discussed AI career opportunity is not only starting an AI automation agency. The bigger and more accessible opportunity for many people is becoming the AI-native version of the function they already know, either by moving from consulting into an in-house role or by being promoted internally because they are already closing th

Harnesses in AI: A Deep Dive — Tejas Kumar, IBM
Kumar argues that reliability in agent systems comes from the harness: everything around the black-box model that grounds it in a stable environment. A harness includes tools, context management, model selection, agent loops, traces, evaluators, and verification. The key claim is that prompt changes alone are often the wrong lever; the surrounding control sy

Why Your AI UX Is Broken (and It’s Not the Model’s Fault) — Mike Christensen, Ably
Christensen argues that many AI chat products feel broken because their UX architecture assumes a single client-server stream. Direct HTTP/SSE streaming is easy to start with but breaks down for resumability, multiple devices/tabs, live control, interruptions, and human handoff. The proposed pattern is a durable session layer that decouples agents from clien

Every Claude Code User NEEDS To Watch This
The video argues that developers should avoid becoming prisoners of one coding-agent vendor. The opening example is Anthropic changing programmatic Claude Code billing, but the broader point is architectural: agent workflows should be portable across models and harnesses because pricing, policy, capabilities, and trust assumptions change quickly.

Agentic Search for Context Engineering — Leonie Monigatti, Elastic
Monigatti argues that context engineering is mostly agentic search: the core problem is deciding which information from many possible sources enters the context window. Fixed RAG pipelines are often insufficient because agents need to choose tools, rewrite queries, search multiple sources, and perform multi-hop retrieval.

Beyond Code Coverage: Functionality Testing with Playwright — Marlene Mhangami, Microsoft
Mhangami’s talk starts from a surge in GitHub commits and asks the right question: more code does not necessarily mean more developer productivity. Her proposed answer is clean-code discipline and functionality testing. In an agentic coding world, TDD and Playwright-style end-to-end tests become more important because agents can create working-looking code f

How we solved Context Management in Agents — Sally-Ann Delucia
Delucia argues that context engineering is the central product problem in serious agent systems: the agent must remember what matters and forget what does not. Her team’s Alex agent ran into the classic loop where the same traces/spans it needed to analyze also overwhelmed the context window. The talk’s most useful framing is that context management is not o

Agents Don’t Do Standups: Building the Post-Engineer Engineering Org — Mike Spitz, PFF
Spitz argues that once AI agents become the implementation bottleneck-breaker, traditional engineering rituals designed around human coordination — especially Scrum ceremonies — should be reconsidered. PFF’s case study claims two strong engineers using agents delivered a high-output product initiative faster than a larger traditional team, with fewer ceremon

Gateways are All You Need — Karan Sampath, Anthropic
Sampath argues that enterprise MCP adoption is blocked by observability, access control, security, credential management, and deployment friction. His solution is a gateway: a trusted middle layer between many MCP servers and many MCP clients that centralizes auth, routing, observability, tunnels, registry, and developer tooling. The thesis is sound for remo

How Building with AI Can Double the Throughput of Your Engineering Team — Brian Scanlan, Intercom
Scanlan argues that Intercom doubled engineering throughput by making AI-assisted development an organizational platform rather than an individual autocomplete habit. The talk’s key components are: executive pressure, one main agent platform, internal skills/plugins, hooks, telemetry, backtesting, automatic review for safe PRs, and a culture where engineers

Everything You Need To Know About Agent Observability — Danny Gollapalli & Zubin Koticha, Raindrop
Raindrop argues that traditional evals are insufficient for production agents because agents are non-deterministic, long-running, tool-using, and exposed to an effectively unbounded input/output space. The proposed answer is production monitoring built around explicit signals, semantic classifiers, regex canaries, experiments, and self-diagnostics. This is a

I’m done.
Theo argues that Anthropic’s new Claude Agent SDK monthly credit is framed as an extra benefit but functionally cuts the value of Claude subscriptions for programmatic and third-party Claude Code workflows. His strongest point is that Anthropic now draws a billing boundary between interactive first-party usage and non-interactive or SDK-based usage, and that

I stopped using /grill-me for coding. Here’s what I use instead:
The video’s thesis is that `/grill-me` is excellent for surfacing ambiguities, but it loses value in codebases because the hard-won shared language often disappears after the conversation. `/grill-with-docs` improves the loop by grounding the interview in existing domain documentation, updating `CONTEXT.md` as language crystallizes, and adding ADRs when deci

Stop letting your agents write Markdown.
Theo evaluates the claim that agents should produce HTML instead of Markdown for richer, more navigable artifacts, agreeing for visual/interactive outputs while pushing back on overbroad “HTML is the new Markdown” rhetoric.

I wish this was clickbait
Theo argues Bun's possible Zig-to-Rust rewrite is both exciting and unsettling: it may address stability and ecosystem concerns, but it also validates doubts about Bun's future and creates migration risk for tools built deeply on Bun-specific APIs.

Codex Just Became THE BEST Long Running Agentic Harness
The creator argues Codex's experimental Goals feature makes long-running autonomous coding easier by turning a hand-rolled Ralph loop into a built-in `/goal` workflow with continuation, budget handling, pause/resume, and completion state.

The EXACT Tools That Make Your AI Apps 10x Safer
The creator argues non-technical builders need a simple safety workflow: use Git branches and pull requests, then run dedicated AI code reviewers on the diff before shipping AI-generated code.

Your Claude Code Agentic OS Sucks
The creator argues that an “agentic OS” is not primarily a fancy dashboard. The real value is a skill and automation backbone, supported by a memory layer; dashboards become useful only after the underlying workflows are reliable.

Anthropic's "dedicated monthly credit" is actually a huge cut
The creator argues Anthropic's dedicated monthly credit for programmatic Claude usage clarifies rules but effectively cuts heavy AFK/background agent users because those workloads now draw from a separate, smaller credit bucket rather than the broader subscription allowance.

32 Tricks to Level Up Claude Code in 16 Mins
The video presents Claude Code as a workflow environment rather than a chatbox: initialize project context, monitor token/cost state, keep context small, plan before acting, use subagents and skills, and embed self-checks so the agent validates its own work.

New Skills! /handoff, /prototype, /review and /writing-* | Skills Changelog
Matt Pocock argues that agent work improves when repeated collaboration patterns become explicit skills: handoff for context transfer, prototype for reducing design uncertainty, XML-tagged prompt sections to control instruction priority, and review/writing skills for repeatable quality loops.

Every Level of Claude Explained in 21 Minutes — analysis
The video argues that Claude users progress through five practical levels: 1. Enthusiast: ad-hoc chat for answers and small tasks. 2. Beginner: projects, memory, connectors, files, artifacts, visuals, and Office integrations. 3. Intermediate: Claude/Cowork-style desktop workflows, skills, scheduled tasks, mobile dispatch/control, design/prototype workflows,

Hermes Agent: Zero to Personal AI Assistant (1 Hour Course)
Hermes is positioned as a self-hosted personal AI assistant that is most useful when it is treated as persistent infrastructure: memory files for durable context, skills for repeatable workflows, soul/personality files for behavior, cron jobs for proactive work, and Git-backed backups for survivability. The video’s practical point is not “Hermes replaces Cla

I Open-Sourced My Own AFK Software Factory — analysis
Matt Pocock argues that useful AFK coding agents need sandboxed execution. Permission prompts make fully unattended work impractical; pure YOLO mode is unsafe; and many existing options are either too service-oriented or awkward to program. His answer is Sandcastle, an open-source TypeScript library that lets developers call `run()` with an agent, sandbox pr

Overwhelmed By AI? Just Copy My Tech Stack — analysis
The creator argues that AI overwhelm comes from chasing every new tool. His answer is a lean stack, a personal North Star, and a decision framework: use daily drivers, keep specialists for specific jobs, experiment intentionally, and “graduate” tools once their useful features are absorbed into your own system. My read: mostly agree. The mindset is stronger

STOP Using Claude Code OR Codex — analysis
The creator argues that choosing between Claude Code and Codex is now the wrong framing. His preferred setup is to use both tools in the same project, let them critique each other, and stay tool-agnostic because agent capabilities and pricing change quickly. My read: mostly agree, with safety caveats. Multi-agent review is a useful pattern, but the video und

Harness Engineering: How to Build Software When Humans Steer, Agents Execute — Ryan Lopopolo, OpenAI
When agents can produce abundant code, the engineering bottleneck moves from implementation to harness design: the systems, repository structure, skills, tests, lints, prompts, documentation, review agents, observability, and feedback loops that let humans steer and agents execute reliably.

Anthropic's Boris Cherny: Why Coding Is Solved, and What Comes Next
The talk’s core thesis is that coding, for some people and some codebases, is shifting from manual code writing to orchestration of AI agents. “Coding is solved” is intentionally provocative: Boris means the code-writing act is solved in his environment, not that software engineering, product judgment, security, reliability, cost control, and domain understa

Claude Code + Paperclip Just Destroyed OpenClaw
The video argues that Paperclip plus Claude Code turns scattered terminal-based agent work into an “AI company” with agents, org charts, projects, approvals, budgets, heartbeats, routines, and skills. My read: the valuable idea is not “zero-human companies”; it is a project-management and governance layer for multiple coding/ops agents that would otherwise l

Learn 90% of Claude Code in 31 Minutes — analysis
The video’s useful thesis is: Claude Code becomes much more effective when treated as an agentic development environment rather than a chat box. The practical loop is: pick an environment, use plan mode, supply outcome/examples/expert questions, add skills for repeatable behavior, manage context aggressively, and connect CLI tools for verification/deployment

18 Claude Code Token Hacks in 18 Minutes
The video argues that Claude Code limits feel worse because long sessions repeatedly reload conversation history, instructions, command outputs, and project context. The proposed solution is token hygiene: shorter sessions, better scoping, smaller outputs, model routing, and explicit context management.

9 Hacks to Use Claude Code Better Than 90% of People (In 9 Minutes)
The video is a rapid list of Claude Code workflow optimizations: choose CLIs over unnecessary MCPs, use side conversations/commands/hooks, manage context aggressively, and encode repeatable tool knowledge as skills or docs.

12 Hidden Settings To Enable In Your Claude Code Setup
The video says Claude Code has many useful configuration, retention, rule-loading, hook, and open-source companion features that are underused because they live in settings files, environment variables, or commands rather than the obvious UI.

Claude Code + LightRAG = UNSTOPPABLE
The video argues that “RAG is dead” is wrong: larger context windows reduce some retrieval needs, but they do not eliminate the need for external memory, updateable corpora, cheaper retrieval, and relationship-aware search. The specific recommendation is LightRAG: a graph-enhanced RAG system that Claude Code can help set up quickly.
Build & Sell Claude Code Operating Systems (2+ Hour Course)
The video reframes AI automation as an operating system: a durable, tool-agnostic layer that knows the business, reaches the right data, performs useful actions, and eventually runs on cadence.
Claude Video Editing Just Became Unrecognizable
Claude Code becomes useful for video editing when it orchestrates specialized tools instead of pretending to be a video editor itself: transcript/cut detection, timeline handoff, motion graphics, and rendering are separate responsibilities.

I Tried 100+ Claude Code Skills. These 6 Are The Best
The video is a practical sales/operator list: the Claude Code skills worth selling are the ones that turn one-off AI into repeatable business systems.

5 Claude Code skills I use every single day
The video is less about five random skills and more about a development pipeline: interrogate the idea, write a PRD, slice it into issues, implement with TDD, and periodically improve architecture.

CLAUDE CODE ADVANCED COURSE — 3 HOURS
This course is a broad operating manual for advanced Claude Code users: memory design, prompt architecture, harnesses, skills, subagents, browser automation, multi-agent orchestration, workspace organization, and security all matter more as the work becomes real.

FULL Guide to Becoming a Principled Agentic Engineer (Build Anything with AI)
The video argues for “principled agentic engineering”: keep humans responsible for planning and validation, but use coding agents as leverage inside a structured loop. The method is intentionally simple: brainstorm with the agent, clarify assumptions, convert the result into PRDs/tickets, implement with a repeatable PIV loop, and feed lessons back into the A

Paperclip: Hire AI Agents Like Employees (Live Demo)
Paperclip is an open-source orchestration layer for managing AI agents as if they were employees: roles, org charts, goals, budgets, skills, routines, and traceable work history.

How to Build Claude Agent Teams Better Than 99% of People
Agent Teams are more powerful than ordinary subagents when teammates need to message each other, share a task list, challenge work, and iterate before returning a final result.

Claude Just Changed the Stock Market Forever! (Tutorial)
The creator claims Claude can connect to Alpaca, market data, congressional/whale-trade feeds, and options workflows to automate retail trading strategies, including trailing stops, copy trading, and the wheel strategy.

This Claude Skill Creates UGC Videos on Autopilot (Claude + Seedance 2.0)
The creator argues that Claude Code plus Arcads/Seedance 2.0 can automate AI-generated UGC ads: analyze a winning social ad, adapt it to a new product, call Arcads via API, and stitch/render variants with minimal manual work.

Top 10 Claude Code Frontend Design Skills, Plugins, & CLIs
This video is a toolkit tour for one specific pain point: Claude Code can generate working frontend code, but its default visual taste is weak and repetitive. The creator’s useful thesis is that frontend quality improves when you stop asking the agent to invent taste from scratch and instead give it stronger design inputs: anti-pattern rules, design-system m

Top 10 NEW Open Source Claude Code Tools (May)
The video is a fast filter over the current open-source Claude Code / coding-agent ecosystem. The creator’s real argument is not “install every shiny repo.” It is: coding agents are becoming more useful when wrapped in small, purpose-built operating layers — brevity constraints, structured memory, video/frame extraction, design-system references, token/cost

How to Build 24/7 Claude Agents. Easy.
Claude Code routines turn Claude from a local, laptop-dependent coding assistant into a remotely triggered automation worker. You can schedule it, call it from APIs/webhooks/GitHub events, give it a repo and cloud environment, and let it run one-shot agent tasks without keeping your computer open. The video’s deeper point is that “remote agents” require diff

I Gave OpenClaw $10,000 to Trade Stocks
The video is a real-money stress test of autonomous AI agents: can OpenClaw run a trading strategy with $10,000 for 30 days, monitor markets, adjust positions, and communicate progress with minimal human intervention? The honest answer from the video is: it can operate autonomously, place and manage trades, and adapt its strategy — but autonomy is not the sa

OpenAI Image 2 is Nuts. Here are 10 Ways to Use it.
The video argues that OpenAI / ChatGPT Images 2.0 has crossed an important threshold: it is no longer just “pretty good at pictures,” but strong enough for practical commercial workflows where text, realism, layout, product detail, and visual editing used to break image models. Nate’s main claim is not that GPT Image 2 wins every prompt. It is that, across m

Hermes Agent Just 10x’d Everyone’s Claude Code
The video argues for a “personal agent on a VPS” workflow: run Hermes as the always-on orchestrator, connect it to chat surfaces like Discord, give it Claude Code as a coding worker, then wire GitHub and Vercel so plain-English messages can become deployed software changes. The strongest version of the idea is not “fire humans and vibe deploy everything.” It

How To De-Slop A Codebase Ruined By AI (with one skill)
AI does not make code architecture irrelevant. It makes architecture debt compound faster. If agents repeatedly change a codebase without understanding its module boundaries, they create duplicated rules, weak seams, and shallow abstractions. The cure is not “use less AI”; it is to make the architecture more legible to both humans and agents through deep mod

ANOTHER Open Source Repo Just Cloned Claude Design
Open Design is an early but credible open-source, GUI-based alternative to Claude Design: essentially Huashu Design plus a polished interface, agent-harness flexibility, built-in design systems, and media-provider hooks. It is not as mature or fast as Claude Design yet, but it already covers enough of the prototype/deck workflow to matter — especially for us

LLM codegen fails and how to stop 'em — Danilo Campos, PostHog
Autonomous codegen works when you stop treating the model as a magic programmer and start treating it as a capable but context-hungry agent that needs fresh documentation, good examples, sequenced instructions, constrained tools, and feedback loops. Danilo’s strongest claim is that the PostHog Wizard succeeds not because it is mostly clever code, but because

Why building eval platforms is hard — Phil Hetzel, Braintrust
An eval platform starts as “a spreadsheet plus a for-loop,” but it quickly becomes a serious agent-quality data system. The real problem is not drawing a comparison UI. The hard part is supporting a continuous loop between offline evals and production observability while storing, searching, scoring, and analyzing enormous semi-structured agent traces. Phil’s

“Software Fundamentals Matter More Than Ever” — Matt Pocock
Matt Pocock argues that AI coding does not make software fundamentals obsolete. It makes them more valuable. If AI can generate code faster, then bad architecture, unclear requirements, weak feedback loops, and ambiguous language become more expensive because they let the agent create chaos at machine speed. His practical message is: > Code is not cheap. Bad

Andrej Karpathy: From Vibe Coding to Agentic Engineering
Karpathy’s central claim is that AI coding has crossed from “helpful autocomplete” into a new engineering substrate: LLMs are becoming a programmable computer for broad information work, not just faster code generation. The practical shift is from writing every instruction yourself to designing context, specifications, feedback loops, and agent-native enviro
Claude Design 2 HOUR COURSE (Beginner to Pro)
This is a long practical walkthrough of Claude Design as a design-production environment: use normal Claude for strategy and thinking, then use Claude Design when you need visual artifacts — design systems, pitch decks, landing pages, app prototypes, and launch videos. The recurring lesson is not “just prompt harder.” It is: prepare context outside the expen

Building pi in a World of Slop — Mario Zechner
Mario argues that current AI coding culture is drowning in “slop”: too much generated code, too little understanding, too many brittle abstractions, and agent tools that hide or mutate context. His answer is pi: a minimal, malleable coding-agent harness where the user and agent control the workflow instead of being boxed into Claude Code/OpenCode-style assum